Within a website, a robots.txt file tells search engines how to crawl pages within the site.
This is part of the REP (Robots Exclusion Protocol) that comprise a series of web standards that govern how robots crawl websites.
The robots.txt file is a simple text file that is hosted on your web server.
Web crawler bots (i.e. from Google) will look for this file and follow its suggestions – which should include a prompt to visit your sitemap.
It is a good idea to have a robots.txt file within your website.
You should be able to find out if your website has one by adding:
/robots.txt
…to the end of your domain name in a website browser.
Here is an image of my robots.txt file:
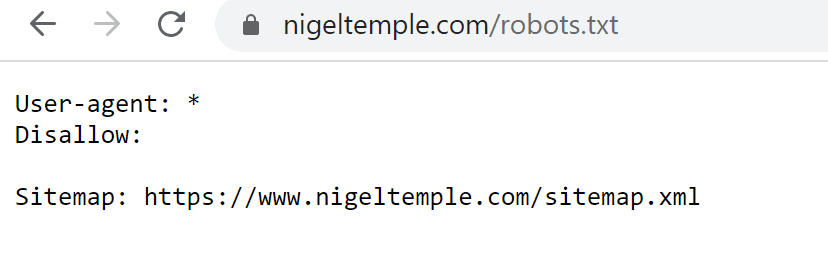
Notice that my sitemap URL is included.